
Storing Data
(Phần 1)

Hi, My name is Phong . I'm a PHP Developer and a weightlifter.
Hãy cũng bàn luận về những cách khác nhau để nhau để lưu trữ dữ liệu.
Data có thể được lưu trữ trong 3 level khác nhau.
Structuring data
- Structured Data
- Unstructured Data
- Semi-structured Data
1. Structured Data
Kiểu dữ liệu dễ tìm kiếm và sắp xếp nhất vì nó thường được chứa trong các hàng, cột và các phần tử của nó có thể được gắn vào các trường cố định được xác định trước, được gọi là Structured Data. Chẳng hạn kiểu dữ liệu có thể lưu trong bảng Excel. Structured Data có thể tuân theo một mô hình dữ liệu mà nhà thiết kế cơ sở dữ liệu tạo ra hay nói cách khác nó có tính mô hình (lược đồ), trong đó các thực thể được nhóm với nhau để tạo relations giúp cho việc lưu trữ và phân tích dễ dàng.
Không chỉ data type và table được định nghĩa, relationships giữa các table cũng được xác định qua khái niệm khóa ngoại (foreign keys).
2. Unstructured Data
Ít mang tính "mô hình (lược đồ)" hơn và dữ liệu sẽ ở dạng rawest, có nghĩa là chưa qua xử lý và không rõ ràng. Các ví dụ về dữ liệu phi cấu trúc bao gồm ảnh, tệp video và âm thanh, tệp văn bản, nội dung mạng xã hội, hình ảnh vệ tinh, bản trình bày, tệp PDF, ... .
Thay vì table hoặc các relationships , unstructured Data thường được lưu trữ trong các Data Lakes, NoSQL databases, applications và Data warehouse. Ngày nay, lượng thông tin phong phú trong Unstructured Data đã có thể truy cập được và có thể được xử lý tự động bằng các thuật toán trí tuệ nhân tạo. Điều này đã giúp Unstructured Data được sử dụng phổ biến.
3. Semi-structured Data
Không theo mô hình, đúng hơn nó có cấu trúc tự mô tả đặc biệt. Là sự kết hợp của 2 cái trên (Structured và Unstructured ), Semi-structured Data không tuân theo cấu trúc cứng nhắc và có tính linh hoạt hơn.
Thư điện tử là một ví dụ điển hình. Mặc dù nội dung thực tế không có cấu trúc nhưng nó chứa dữ liệu có cấu trúc như tên và địa chỉ email của người gửi và người nhận, thời gian gửi, v.v.

Tóm lại, đối với data, Structured Data có thể dễ dàng tổ chức và tuân theo một định dạng cứng nhắc; Unstructured Data là thông tin phức tạp và thường là thông tin định tính không thể giảm bớt hoặc sắp xếp trong cơ sở dữ liệu quan hệ và Semi-structured Data có các yếu tố của cả hai.
Storing data
Bạn chắc hẳn đã biết đến Traditional databases, chúng thường tuân theo lược đồ quan hệ để lưu trữ structured data theo thời gian thực. (OLTP là một ví dụ). Traditional databases được sử dụng rộng rãi cho việc lưu trữ dữ liệu vào thập kỷ trước. Sau đó, nhu cầu và sự phát triển của việc phân tích dữ liệu đã khiến cho Data warehouses được sử dụng phổ biến bởi nó phù hợp cho phương thức OLAP. Và đến hiện nay, kỷ nguyên của Big data, chúng ta cần phân tích và lưu trữ một lượng dữ liệu lớn và đó là lý do Data Lakes ra đời với tính linh hoạt và khả năng mở rộng.
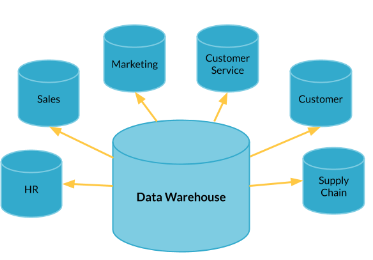
1. Data warehouses
- Tùy chỉnh phù hợp cho việc phân tích - OLAP.
- Được sắp xếp và tổ chức cho việc đọc và tổng hợp dữ liệu
- Thường là Read-only.
- Chứa data từ rất nhiều nguồn.
- Sử dụng MPP(massively parallel processing) cho việc truy vấn nhanh hơn.
Thường sử dụng mô hình đa chiều và không theo mô hình chuẩn hóa trong việc thiết kế. Amazon, Google và Microsoft đều cung cấp các giải pháp Data warehouses, được biết đến như là Redshift, Big Query, và Azure Data warehouses.
Một khái niệm khác là Data marts, được xem như là "con" của Data warehouses, và được thiết kế dành riêng cho một chủ đề cụ thể. Cho phép các phòng ban có quyền truy cập dễ dàng hơn vào dữ liệu quan trọng đối với họ.
2. Data Lakes
Về mặt kỹ thuật, Traditional databases và warehouses có thể lưu trữ unstructured data, tuy nhiên khá tốn kém. Data Lakes thì rẻ hơn bởi vì sử dụng lưu trữ object thay vì lưu trữ block hoặc file truyền thống.
Cho phép lưu trữ một lượng lớn thông tin, dữ liệu với đa dạng type (raw, operational data, IoT device logs, real-time, relational hoặc non-relational ) từ truyền cho đến sử dụng dữ liệu. Cũng vì vậy mà Lakes có dung lượng rất lớn (thường là petabytes - 1000 terabytes!) nên Unstructured data là phù hợp nhất vì nó dễ mở rộng và cho phép kích thước này. Lakes là một schema-on-read, nghĩa là lược đồ được tạo khi dữ liệu được đọc, trái ngược với schema-on-write (Traditional databases và warehouses).
Data Lakes được tổ chức và phân loại tốt; nếu không nó đã được gọi là "Data swamp( Đầm lầy )" . Nó rất hữu dụng cho deep learning và data discovery. .Và tất nhiên bộ ba Cloud provider đều cung cấp các giải pháp Data Lakes.
(Còn tiếp ) .




